
AWS Cloud Searchを使用して静的コンテンツに検索機能をつける
こんにちはjunです。静的書き出しブログを作って数ヶ月後、ようやくこのブログにも「検索機能」を実装しました。静的ファイルの場合は検索といった動的な機能をつける際には工夫が必要です。
wordpressなどでは自身のプログラムとデータベースを用いて検索を行いますが、静的ブログではその2つがないので別途で準備する必要があります。つまり検索プログラムと検索対象のファイルをどこかに置き、さらにサイトからAjaxを用いてアクセスできるようにします。
私のサイトでは検索エンジンに「AWS Cloudsearch」というものを用いて実装しています。今回の記事でも同じようにCloudsearchを用いての解説を行います。
全体の概要
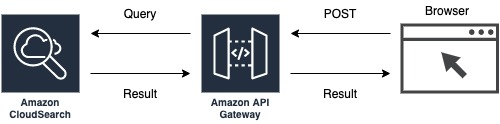
概要は上図のような感じです。検索機能自体はcloudsearchに任せ、cloudsearchを叩くAPI gatewayを通じてブラウザからアクセスします。これらの構成を実現するために以下の手順の実装が必要となります。
- cloudsearchのインスタンス作成
- 検索対象のドキュメント(JSON)をcloudsearchにアップロード
- API gateqwayからcloudsearchを叩くように連携
- ウェブサイトから検索クエリを持たせたリクエストでAPIを叩く
- 結果をサイトに表示
それぞれの手順通りに説明していきます。
cloudsearchのセットアップ
cloudsearchのインスタンスを作成
AWSのアカウント作成などは省略します。AWSのメニューからcloudsearchに移動します。リージョンを確認して、「Create a new search domain」をクリックして検索インスタンスを作成します。ここでいうドメインはURLのドメインという意味でなく、「Domain」は検索の区分みたいなものです。
インスタンスの大きさなどを選択できますが、今回は一番小さいものにしておきます。Desired Instance Typeをsearch.small、Desired Replication Countを1にしました。
インデックスフィールドの登録
次に検索対象のインデックスフィールドを登録します。
ここでいうインデックスフィールドとはタイトル、内容、カテゴリー、作成日時といった各ドキュメントの属性のことをいいます。インデックスフィールドを設定することでタイトルで検索、内容で検索、特定日時からの検索といった複雑な検索ができます。RDBでいうところのカラムみたいなものです。
もしドキュメントがある場合はAnalyze sample file(s) from my local machineを選択しファイルをアップロードします。使用できるファイルはXML,JSON,CSVがサポートされています。(詳細はこちら)アップロードされたファイルから共通のインデックスフィールドを自動で設定してくれます。
私の場合は以下のようなcloudsearchの使用に従った構成でサンプルJSONを予め作成しておきました。
[
{
"type":"add",
"id":"bag-html-break-tag",
"fields":{
"description":"white-space: pre;で要素内で生じる、文章の隙間、インテンドの原因。",
"title":"white-space: pre;で要素内で生じる文章の隙間、インテンドの原因。",
"category":["ministack"],
"tag":["html","css","vue"],
"path":"https://jun-app.com/articles/bag-html-break-tag",
"content":"~~~~~~~~~"
}
}
]
この場合、fieldsにある項目が自動に読みとれ、以下のように設定されます。
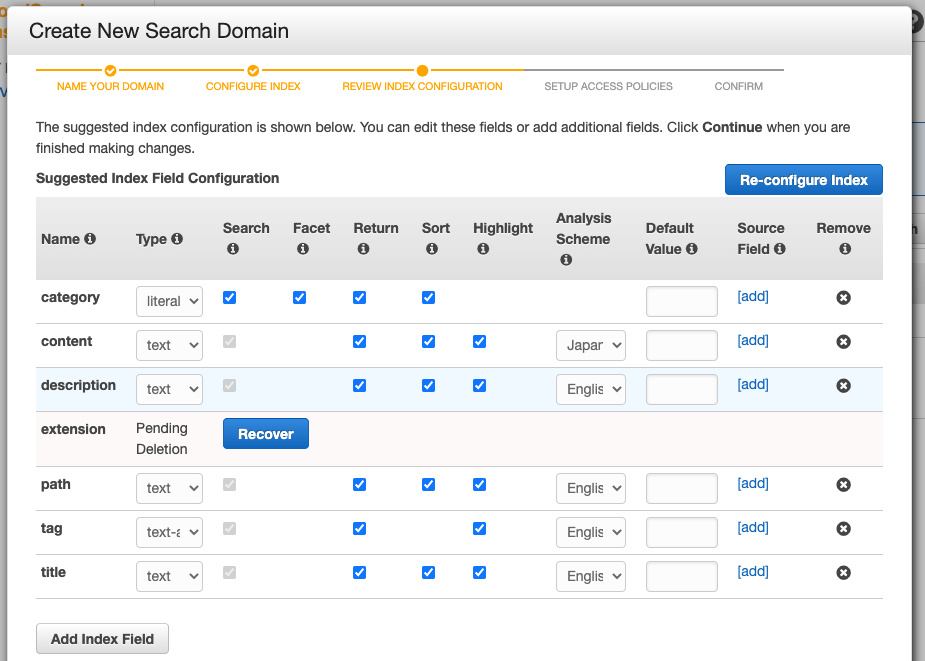
インデックスフィールドの設定詳細はこちらを参考にしてください。
アクセスポリシーの追加
次にこのcloudsearchインスタンスに対するアクセスポリシーを設定します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "*"
},
"Action": [
"cloudsearch:search",
"cloudsearch:suggest"
]
}
]
}
もう少し厳密にしたい人は "AWS": "*"をロールベースにするなどします。これでAWSのサービス、すなわちAPI gatewayがこのcloudsearchの検索機能を使用できるようになりました。
セットアップ完了
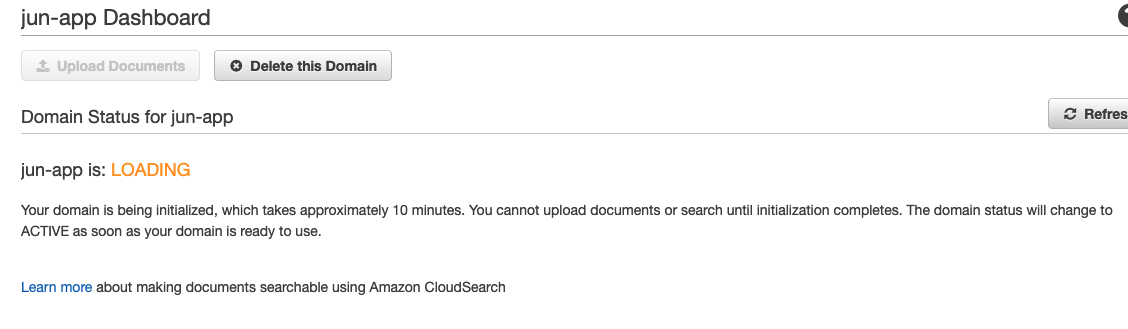
最後に確認をして適用します。設定の適用には10分ぐらい時間がかかるので気長に待ちます。この時は他の文書をアップロードするなどもできなくなります。

このLOADINGという文字がACTIVEに変われば他の操作ができるようになります。
API gatewayの準備
cloudsearchの処理が完了する間、API gatewayも実装しましょう。公式では「Amazon CloudSearch と API Gateway の統合」 こちらの記事が大変参考になります。
新しいAPIの作成まで行ったら、GETメソッドのAPIを選択します。そして「統合リクエスト」を選択します。ここでリクエストをAWSのサービスに連絡させます。

上記の黒塗りにした箇所はcloudsearchのダッシュボードにある値を入れます。「AWSサブドメイン」は「Search Endpoint」、「実行ロール」はAPI gatewayがcloudsearchを叩くためのロールのARNを入れます。そのロールの作成はこちら を確認してください。
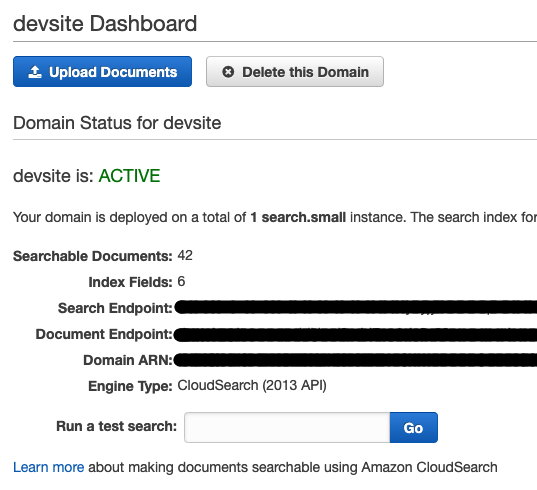
最後に「URL クエリ文字列パラメータ」に「q」という名前でAPI gatewaryに含まれる method.request.querystring.qをマッピングします。こうすることでクライアントからきたcloudsearchのクエリが、API gatewayを通じて実際のcloudsearchに渡されるようになりました。
次に「統合リクエスト」から一つ前の画面に戻って「メソッドリクエスト」の画面を開き、「リクエストの検証」の項目で「クエリ文字列パラメーターおよびヘッダーの検証」を選択します。そして先ほど設定したクエリパラメータ「q」を必須にするため、「URL クエリ文字列パラメータ」を開いて名前に「q」として必須にして確定します。こうすることで必ずリクエストにはcloudsearchで検索を行うためのクエリ文が含まれるようになりました。
テストを行い、クエリ文字列にq=testみたいに入れて送ってみましょう。ステータスが200で以下のようなレスポンスボディがあればcloudsearchが検索結果を返しています。
{
"status": {
"rid": "~~~~~~",
"time-ms": 1
},
"hits": {
"found": 0,
"start": 0,
"hit": []
}
}
何も文書をアップロードしていなければhitしませんし、そしてCloudsearchがLOADINGだと返してくれないことがあります。テストが完了したらAPIをデプロイしてAPI gatewayの設定は完了です。あとはクライアントから適当に叩いてください。
文書(ページ)をアップロードする
それでは検索させる文書、静的ページの内容をアップロードしましょう。先述の通り以下のような形式のJSONにまとめます。
[
// ここから
{
"type":"add",
"id":"bag-html-break-tag",
"fields":{
"description":"white-space: pre;で要素内で生じる、文章の隙間、インテンドの原因。",
"title":"white-space: pre;で要素内で生じる文章の隙間、インテンドの原因。",
"category":["ministack"],
"tag":["html","css","vue"],
"path":"https://jun-app.com/articles/bag-html-break-tag",
"content":"~~~~~~~~~"
}
},
// これで1件の文書を追加するという意味。
{
...
},
...
]
ここでアップロードの際には上記のようなtype,id,fields の3つのプロパティーを持つ必要があります。idは重複すると上書きされてしまうので、必ず異なるようにします。また後からわかるように何らかの規則があると、削除や上書きが簡単になります。私の場合は記事のマークダウンファイルの名前から取っています。私のブログはnuxt contentを使用しているのでnode.jsをいじってうんちゃらしています。頑張って文書分のjsonを用意してください。
json化する際の注意点
文書のアップロードを行う時に失敗すると以下のような画面が表示されます。
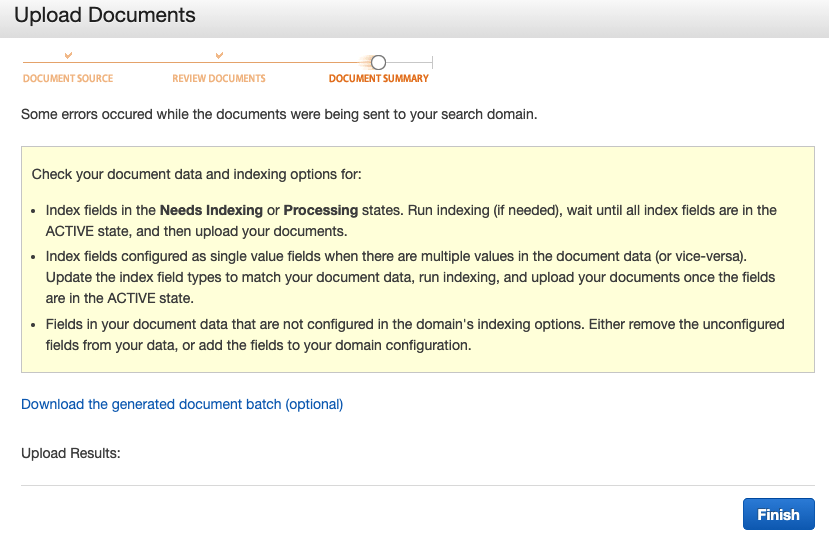
アップロードが失敗する原因と対策としてこの英文の通り
- cloudsearchがACTIVEでなくLOADINGやNEED INDEX状態であるので、ACTIVEになるまで待つこと。(またはindex optionsでインデックスを走らせる)
- single valueとして定義されたフィールドになっているのに、文書に複数の値が入っている。(自分もよくわからん)
- cloudserachで定義されていないフィールドが文書にある。またはその逆。フィールドの設定をもう一度見直すか、文書のフィールドを設定し直す。
となります。
ただしフィールドなどを正しくしても何度も治らず、いろいろ検索しました。すると公式ドキュメントのこの箇所に解決策と思われる内容がありました。
つまり作成したJSONに無効なURF-8文字列が含まれており、エラーが起きていたのです。アップロードエラーには表示されないのでかなり詰まりました。
今回のjsonの場合、titleとcontentに対して上記の正規表現を使って無効な文字列を削除してます。node.jsの場合は以下の通りです。
data = data.replace(
/[^\u0009\u000a\u000d\u0020-\uD7FF\uE000-\uFFFD]/g,
''
);
こうして直したjsonは無事、なんとかアップロードできました。どうやって見つけたかというと、1文書だけをいくつかのパターンに分けてアップロードすると、できるものとできないものがあって「使用される文字列が原因か?」となったのが決定打でした。
テスト
Run a Test Searchにてクエリをテストして、文章がきちんと検索されているか、アップロードされているかをチェックしましょう。
クライアント側の実装
これで検索機能の準備ができたので、API gatewayから必要なエンドポイントなどを取得してアクセスしてみましょう。
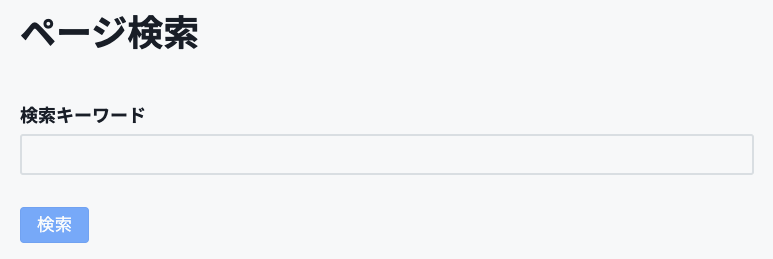
ページ上ではこのようなUIとして、入力したキーワードで検索できるようにします。cloudsearchは複雑なクエリを組むこともできるのですが、今回は単純なものにします。
await fetch('https://sample.sa-sample-1.amazonaws.com/v1?q='+this.query,{
method:'GET',
headers: {
'Content-Type': 'application/json'
},
})
.then(response => response.json())
.then(jsondata => {
this.result = jsondata
)
方法は単純でバリデーションを行った後に、API gatewayのエンドポイントにクエリ付きでアクセスします。
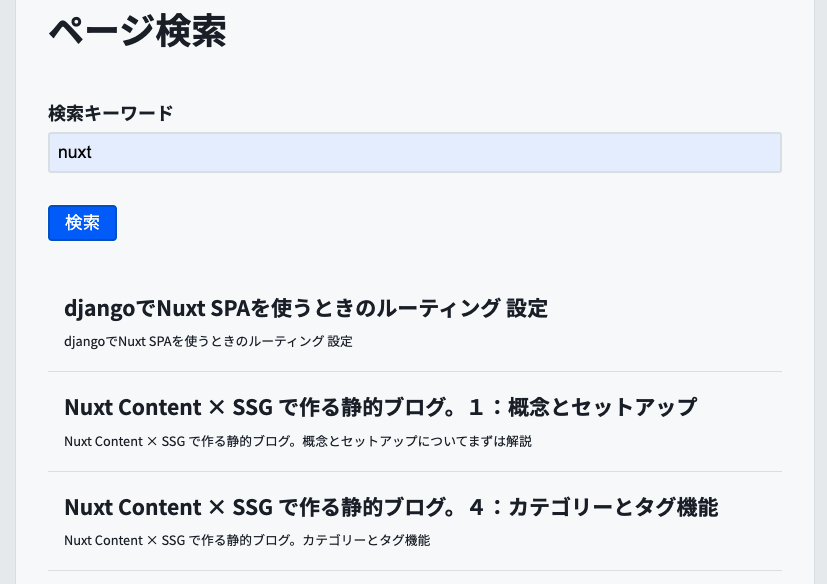
ページのURLなどもフィールドを含まれており、レスポンスで返すようにしています。それを用いてこのように一覧のリンクを作れば検索機能は実装完了です。
今回は検索エンジンにAWS cloudsearchを使用しましたが、他にも文書検索サービスはたくさんあります。商用で利用する場合は検索文書を自動的にアップロードしたりする機能や、より複雑なクエリの構築、キャッシュの利用が必要となります。
以上が静的ページに検索機能を持たせる方法です。最後見てくださりありがとうございました。